【开源】使用可穿戴相机为视障人士提供社交距离反馈


“这篇文章是我用来记录,我在OpenCV人工智能竞赛中为盲人开发的社交距离反馈系统。”
— Ibai Gorordo(九州工业大学博士)
第一部分——初始设置+深度
OpenCV空间人工智能竞赛
最近,OpenCV发起了由英特尔赞助的OpenCV空间AI竞赛,作为OpenCV20周年献礼的一部分。比赛的主要目标是根据OAK-D做开发应用。比赛分为两个阶段,第一阶段的获胜者能够免费获得OAK-D来开发他们的应用,第二阶段的获胜者将获得高达3000美元的现金奖励。
OAK-D包含一个用于深度神经推理的1200万像素RGB摄像头和一个立体双目摄像头,用于使用英特尔的Myriad X视觉处理单元(VPU)实时进行深度估计。
如果你想了解更多关于OAK-D的信息,请务必查看Ritesh Kanjee对Brandon Gilles的采访,他是OpenCV AI工具包的首席架构师。OAK-D在Kickstarter上已经筹集了超过300万美元的资金,支持者超过6000人。如果你有兴趣,你也可以在这里找到更多关于OAK的信息。
由于OAK-D的有趣功能,我决定申请OpenCV空间人工智能竞赛,并幸运地被选为第一阶段的获胜者之一。你也可以在这里查看第一阶段其他获奖者的项目。
这篇文章是一系列文章的一部分,我将描述我使用OAK-D开发的过程。
拟议系统

我提案的标题是 “使用可穿戴相机为视障人士提供社交距离反馈”。由于目前新冠肺炎在世界范围内的爆发,社交距离已经成为一种新的社会规范,作为防止新冠肺炎广泛传播的措施。
然而,视障人士正努力在新的社会疏远常态下保持独立¹,²。对于盲人来说,不可能轻易确认他们是否与周围的人保持了社交距离。例如,英国皇家全国盲人协会(RNIB)推特账户中的一段视频显示了盲人在日常生活中因社会距离而面临的困难。
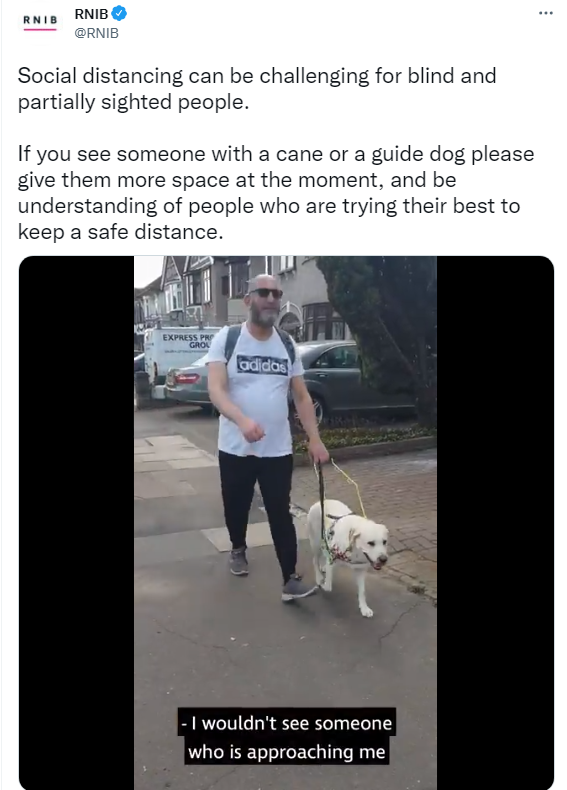
此外,常见的盲人解决方案(如白手杖或狗)无法帮助盲人保持社交距离。更糟糕的是,盲人无法知道他们身边的人是否戴着口罩,因此他们被感染的风险更高。
出于这些原因,我的项目的目标是为盲人开发一个反馈系统,告知他们与周围其他人的距离以及某人是否没有戴口罩。
对于这类项目,深度和人工智能需要实时结合,OAK-D是理想的系统。如OAK的一个示例所示,能够实时检测图像中人脸的位置,以及他们是否戴着口罩。通过将该信息与从立体相机获得的深度信息相结合,可以估计用户周围的人的位置以及某人是否没有戴口罩。
然后,该系统将使用连接到OAK-D板上的五个触觉电机通知用户与周围人的距离。触觉电机将与5个方向角:-40度,-20度,0度,20度和40度。例如,如果系统检测到有人在-20度角附近(如上图所示),那么左边第二个电机将会振动。此外,为了告知人有多近,马达的强度将随着被检测的人越来越近而变化。最后,如果系统检测到有人没有戴口罩,系统将通过改变振动模式来告知用户。
Windows安装和初始测试
本周我收到了OAK-D套件。如下图所示,该套件包含一个OAK-D,一个Type-C线,一个5V (3A)充电器和一个3D打印的GoPro支架。

OAK-D的尺寸较小(46 x 100毫米),呈T形。实际上,板的下部与Raspberry Pi Zero的宽度差不多,因此将两块板组合在一起的系统可以具有紧凑的尺寸,如下图所示。

为了与OAK-D连接,Luxonis的工程师们开发了DepthAI Python API。DepthAI API是开源的,可以运行在不同的操作系统中,包括Windows,Ubuntu、Raspbian和macOS。
一旦我安装了depthAI API及其依赖项,我就可以通过运行以下命令来运行默认演示程序(确保位于depthAI文件夹中):
python depthai.py该演示默认运行MobileNet SSD物体检测模型,可以检测图像中20种不同类型的物体(自行车、汽车、猫…)。此外,该演示将检测到的物体的边界框与立体摄像机的深度信息相结合,以提供每个检测到的物体的三维位置。作为一个例子,下面我展示了一个检测水瓶的演示输出,水瓶是可以检测默认演示模型的类别之一。

该演示能够跟踪物体,并以30帧的速度计算深度,没有任何问题。通过查看depthai.py脚本的Python代码,我看到该演示可以通过在运行该演示时添加参数来配置成其他模式。例如,运行下面的代码,就可以获得彩色的深度(注意:只适用于Windows 10的Refactory版本,在原始仓库中,配置已经改变)。
python depthai.py --streams depth_color_h
总的来说,在背景的左边有一些黑色区域,深度看起来相当不错。然而,该区域包含玻璃面板,并且可能立体相机系统不能从中提取许多特征,因此这些区域没有深度信息。
深度估计:OAK-D与Azure Kinect DK
尽管OAK-D的深度估计不是它的主要功能,但我想将OAK-D的深度估计与最新的Azure Kinect DK进行比较。为此,我修改写了一个小的Python脚本(hello_depth.py)读取原始深度值并像在Azure Kinect中一样显尽管OAK-D的深度估计不是它的主要功能,但我想把OAK-D的深度估计与最新的Azure Kinect DK进行比较。为此,我修改写了一个小的Python脚本(hello_depth.py),读取原始deoth值并显示Azure Kinect的深度。
import numpy as np # numpy - manipulate the packet data returned by depthai
import cv2 # opencv - display the video stream
import depthai # access the camera and its data packets
import consts.resource_paths # load paths to depthai resources
import os
device = depthai.Device("", False)
# Create the pipeline using the 'depth_sipp' stream, establishing the first connection to the device.
pipeline = device.create_pipeline(config={
'streams': ['depth_sipp'],
'ai': {
"blob_file": consts.resource_paths.blob_fpath,
"blob_file_config": consts.resource_paths.blob_config_fpath,
}
})
if pipeline is None:
raise RuntimeError('Pipeline creation failed!')
while True:
# Retrieve data packets from the device.
# A data packet contains the video frame data.
nnet_packets, data_packets = pipeline.get_available_nnet_and_data_packets()
for packet in data_packets:
if packet.stream_name.startswith('depth'):
frame = packet.getData()
frame[frame > 60000] = 0
frame = (frame // 30).astype(np.uint8)
#colorize depth map, comment out code below to obtain grayscale
frame = cv2.applyColorMap(frame, cv2.COLORMAP_JET)
cv2.imshow(packet.stream_name, frame)
if cv2.waitKey(1) == ord('q'):
break
# The pipeline object should be deleted after exiting the loop. Otherwise device will continue working.
# This is required if you are going to add code after exiting the loop.
del pipeline
os._exit(0)至于Azure Kinect,我使用了Azure Kinect SDK的Python资源库中的深度估计示例程序。在下面的图片中,对两个设备的估计深度进行了比较。

可以看到,尽管OAK-D使用了立体相机,但效果非常好。特别是在有桌子的情况下,OAK-D能够正确地估计深度,而Azure Kinect中的TOF传感器却失败了。
这是第一部分的全部内容,在下一部分中,我将使用OAK-D测试口罩检测示例。我还将在我的资源库中上传这个项目的所有脚本。
参考
[1]: Gus Alexiou. (June 7 2020). Blind People’s Social Distancing Nightmare To Intensify As Lockdowns Ease
[2]: BBC news. (June 24 2020). Social distancing a ‘struggle’ for those visually impaired
第二部分——口罩检测器
为什么要做口罩检测?
正如该系列第一部分所述,这个项目的目的是为盲人开发一个反馈系统,帮助他们使用OAK-D与周围的人保持社交距离。在这篇文章中,我将专注于使用深度学习模型对周围的人进行检测,以便与这些人保持距离。
对用户周围的人的检测可以通过多种方式进行,一种选择可以是像这个资源库中那样训练一个行人检测模型。另一个可能的选择是只检测人脸而不是检测整个身体。人脸检测模型的好处是,由于人脸的独特特征,即使不需要深度学习模型,也能更容易地检测人脸。例如,在这个OpenCV教程中,一个基于Haar特征的级联分类器方法被用来实时检测人脸,即使是在低性能计算设备中。
然而,在这个特定的应用中,我们还想知道周围的人是否戴着口罩。那么,最好的选择是只使用一个模型来检测人们在哪里,以及他们是否在使用口罩,即口罩检测器。
丰富的口罩检测示例
由于在目前的新冠肺炎疫情中,口罩的使用越来越多,有很多人开发了口罩检测系统。在Github上快速搜索 “face mask detection“,可以得到大约700个关于该主题的资源库。同样地,在Youtube上搜索同一术语,会得到一连串展示人脸检测模型实施的视频。
因此,在如此多的可用示例中,我预计应该很容易找到一个对OAK-D来说足够快的示例,而且即使在现实生活环境中也有很好的准确性。
然而,我们应该选择哪个人脸口罩检测示例?
首先,我决定查看Github。下表总结了其中一些存储库中使用的数据集和模型列表。面罩检测示例概述
| Author | Dataset | Model | Input shape | Platform | URL | |
| FaceMaskDetection | AIZOOTech | AIZOOTech (7959 images) | Small CNN (SSD) | 260 x 260 | Multiple | https://github.com/AIZOOTech/FaceMaskDetection |
| Face-Mask-Detection | chandrikadeb7 | Custom (3835 images) | ResNet (SSD) (face detection) + MovileNetV2 (mask classification) | 300 x 300 (face detection) + 224 x 224 (mask classification) | Tensorflow + OpenCV | https://github.com/chandrikadeb7/Face-Mask-Detection |
| face-mask-detection-tf2 | PureHing | Modified AIZOOTech (7959 images) | Mobilenet + RFB (SSD) | 240 x 240 | Tensorflow 2.1 | https://github.com/PureHing/face-mask-detection-tf2 |
| Face-Mask-Detection | mk-gurucharan | Prajna Bhandary鈥檚 dataset (1376 images) Cascade | Classifier for face detection + very small CNN for face mask classification | 150 x 150 | Tensorflow + OpenCV | https://github.com/mk-gurucharan/Face-Mask-Detection |
| face_mask_detection | Spidy20 | Custom (using webcam) | faster_rcnn_inception_v2 | 312 x 224 | Tensorflow | https://github.com/Spidy20/face_mask_detection |
| yolov4_face_mask_detection | Backl1ght | AIZOOTech (7959 images) | YoloV4 | 608 x 608 | Keras | https://github.com/Backl1ght/yolov4_face_mask_detection |
从搜索结果中可以发现,有两种主要方式来执行口罩检测:1.人脸检测+每个检测到的人脸上的人脸面具分类或者2.直接执行口罩检测。第一种方法可能具有更好的准确性,因为可用的人脸检测模型已经在成千上万的人脸图像中被训练。相比之下,如表中所示,人脸口罩检测数据集具有较少的用于训练的图像,其中AIZOOTech数据集有更多的图像。
然而,大多数先前的人脸检测模型是在未被覆盖的人脸上训练的。由于这个原因,在脸部被遮罩的情况下,脸部检测模型可能会失效(正如pyimagesearch.com中非常详细的文章所解释的)。
基于OAK-D的人脸口罩检测
在分析前面提到的例子之前,Luxonis已经提供了一个使用OAK-D进行人脸口罩检测的示例,示例中的模型是一个在Google Colab中训练的MobileNetV2(SSD)。
注意:尽管示例中没有包括这个模型,但他们也提供了另一个Google Colab脚本,用于训练一个用于面罩检测的YOLOv3-tiny模型。
为了运行该示例,有必要安装DepthAI Python。我还修改了该示例,你可以在我的Github仓库中找到这个项目。要运行该示例,有必要按照前面的解释安装DepthAI库,并将depthai文件夹添加到你系统的PYTHONPATH中。接下来打开命令,运行以下命令:
git clone https://github.com/ibaiGorordo/Social-Distance-Feedback.git
cd "Social-Distance-Feedback\Part 2 - Mask Detection"
python demo_mask_detector.pydemo_mask_detector.py是一个脚本,用于配置OAK-D在RGB相机上进行人脸口罩检测,并显示OAK-D的图像和检测结果。
import numpy as np
import cv2
from demo_helpers import config, capture_image, get_detection, calculate_frame_speed, decode_mobilenet_ssd, show_mobilenet_ssd
from time import time, sleep, monotonic
import os
import depthai
print('Using depthai module from: ', depthai.__file__)
# Create a list of enabled streams ()
stream_names = ['metaout', 'previewout']
device = depthai.Device('', False)
# create the pipeline, here is the first connection with the device
p = device.create_pipeline(config=config)
if p is None:
print('Pipeline is not created.')
exit(3)
while True:
# retreive data from the device
# data is stored in packets, there are nnet (Neural NETwork) packets which have additional functions for NNet result interpretation
nnet_packets, data_packets = p.get_available_nnet_and_data_packets(True)
ret, frame = capture_image(data_packets)
nnet_prev = get_detection(nnet_packets)
if ret:
frame_count = calculate_frame_speed()
nn_frame = show_mobilenet_ssd(nnet_prev["entries_prev"]['rgb'], frame, is_depth=0)
cv2.putText(nn_frame, "fps: " + str(frame_count), (25, 50), cv2.FONT_HERSHEY_SIMPLEX, 1.0, (0, 0, 0))
cv2.imshow("Mask detection", nn_frame)
key = cv2.waitKey(1)
if key == ord('q'):
break
del p # in order to stop the pipeline object should be deleted, otherwise device will continue working. This is required if you are going to add code after the main loop, otherwise you can ommit it.
device.deinit_device()
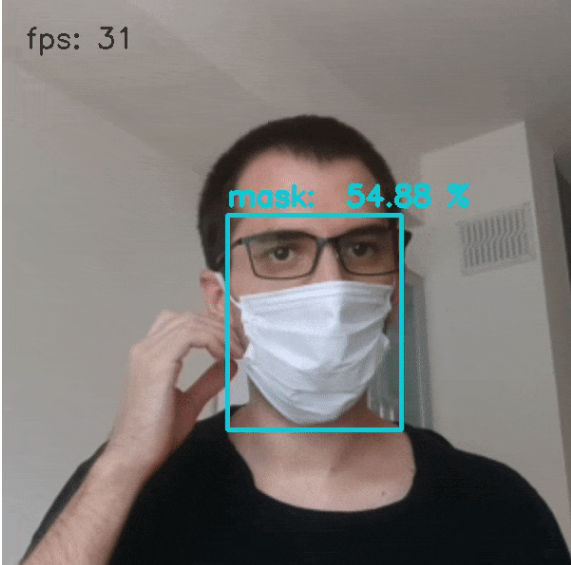
print('py: DONE.')下图显示了OAK-D对MobileNetV2(SSD)人脸口罩检测模型(使用DepthAI的Google Colab脚本训练)的推理输出。
人脸口罩检测模型在户外表现怎么样?
前面的例子与许多教程类似,这些教程最后都有一个使用网络摄像头进行推理的例子。然而,我的系统的目标是在日常生活中使用,特别是在户外。因此,该系统在不同的光线条件下,甚至在周围有多人的情况下都应该是稳定的。
出于这个原因,我决定看看不同的人脸面具检测模型在一个更真实的环境中是如何表现的。为此,我使用了这个来自pexels.com的视频,视频中人们在夜市中行走。下面的视频显示了SSD-MobileNetV2与使用DepthAI的Google Colab脚本训练的YOLOv3-tiny模型的脸部面具检测的比较。推理程序的代码可以在我的Github资源库中找到,这里。
可以看出,SSD-MobilenetV2模型有更多的检测,但结果是,这些检测中有更多的是错误的检测。即使将置信度阈值提高到0.7(如上面的视频),SSD-MobilenetV2模型仍然有大量的错误检测。
另一方面,YOLOv3-tiny模型漏掉了一些人脸(特别是离得远的人脸),但在置信度阈值为0.5的情况下,检测结果比较稳定。由于我们的应用只需要检测靠近用户的人(距离为3米或更近),YOLOv3-tiny模型似乎是这两个模型中最有前途的一个。
YOLOv4呢?
最近,Alexey Bochkovskiy提出了一个新的YOLO版本(YOLOv4),它提供了比以前版本更高的性能。在下面的视频中,有一个例子来自Mladen Zamanov。可以看出,即使周围有很多人,YOLOv4也能进行人脸面具检测。
在我们的应用中使用YOLOv4的问题是,为了将模型传递给OAK-D,需要将模型转换为一个.blob文件,以便由OAK-D内的Myriad X运行。然而,为了转换模型,必须使用OpenVINO工具包的模型优化器。
我在Google Colab中使用这个脚本(代码如下)训练了YOLOv4-tiny模型,这个脚本是基于DepthAI的原始脚本。在同一个脚本中,我还添加了代码,在我用来比较SSD-MobileNetV2和YOLOv3的同一视频上检测脸部面具。
可以看出,两个模型的结果非常相似。在某些情况下,YOLOv4-tiny能够检测到YOLOv3-tiny无法检测到的人脸,但总体而言,其结果几乎是相同的。
代码地址
所有代码都可以在我的资源库中找到。