OAK相机depthai最全上手教程

| 本篇教程来自Luxonis的官方使用文档,由OAK中国翻译编辑。部分链接如果打不开,可能是因为外网原因。 |
depthai用户你好!
在本指南中,我假设你刚刚拿到了OAK相机(例如OAK-D),并且这是你的首次尝试使用,现在我们来看看你能拿它实现什么。
- 首先,我们将运行一个depthai demo脚本,预览depthai的功能。
- 接下来,我将介绍demo脚本中的一些可用选项,并展示它们的用法。
- 最后,附上一些参考链接,以做扩展。参考开源用例、代码示例和教程,你可以依此开始你自己的项目了。
让我们从下面的设备设置开始!
▌连接OAK USB系列相机
如果你的OAK附带了USB线,我们建议使用该线将OAK相机连接到主机。
| ⚠警告!请一定要使用USB3.0的线,如果你用的是2.0的线,请强制使用 USB2 通信。 |

USB3.0 Type-C线的USB-A端连接器内部是蓝色的。
确保设备与你的主机(可以是PC或树莓派或其他有可用的设备)直接连接到USB端口,或通过可供电的USB hub连接。
在Ubuntu上,你可以通过运行以下命令来检查是否检测到新的USB设备。
$ lsusb | grep MyriadX Bus 003 Device 002: ID 03e7:2485 Intel Movidius MyriadX
| ⚠注意!如果你运行的是Ubuntu以外的操作系统,或者你认为有什么地方出错了,我们有详细的操作系统安装指南(查看)。 |
▌连接OAK PoE系列相机
如果你使用的是PoE设备,请参照OAK PoE设备入门教程操作。
▌使用Windows Installer
如果你愿意,我们已经将所有设置过程封装在一个.exe文件里,你可以在这里下载,跳过下面设置这部分内容。
下载并运行后,它将安装所有必需的组件和软件包需求。一旦完成,它将自动运行demo脚本。
▌设置
在这一节中,我将描述如何用命令行手动安装demo脚本。
下载demo脚本
要下载demo脚本,你可以使用git或者直接下载一个zip文件。
从zip文件
首先下载存储库包,然后将归档文件解压缩到一个首选目录。接下来,在这个目录中打开一个终端会话。
来自git
首先,打开终端会话,转到你想要下载demo脚本的首选目录。然后,运行以下代码下载demo脚本。
$ git clone https://github.com/luxonis/depthai.git
下载存储库后,确保通过运行以下命令进入下载的存储库。
$ cd depthai
创建python virtualenv(可选)
要创建和使用virtualenv,你可以按照virtualenvs官方python指南或者遵循网络上特定操作系统的指南,例如“如何在Ubuntu 20.04上创建Python 3虚拟环境”。
这将确保你使用的是一个全新的环境,并且Python 3是默认的解释器——这有助于防止潜在的问题。
我通常通过运行以下代码来创建和使用virtualenvs:
$ python3 -m venv myvenv $ source myvenv/bin/activate $ pip install -U pip
这可能需要事先安装这些软件包:
$ apt-get install python3-pip python3-venv
安装requirements
一旦下载了demo源代码,并且设置了终端会话,接下来要做的事情就是安装这个脚本需要的所有附加包(连同depthai Python API本身)。
要安装这些软件包,请运行install_requirements.py脚本:
$ python3 install_requirements.py
⚠警告!如果你使用的是Linux系统,在大多数情况下,你必须为我们的脚本添加一个新的udev规则,以便能够正确地访问设备。你可以通过运行以下命令来添加和应用新规则:$ echo 'SUBSYSTEM=="usb", ATTRS{idVendor}=="03e7", MODE="0666"' | sudo tee /etc/udev/rules.d/80-movidius.rules $ sudo udevadm control --reload-rules && sudo udevadm trigger |
现在,你应该能够开始使用demo脚本了,我们现在就开始。
运行demo脚本
设置好一切后,我们现在可以运行以下命令来使用demo脚本了:
$ python3 depthai_demo.py
▌默认运行
第一次运行demo时,脚本将编译并下载一个默认的MobileNet-ssd模型,配置OAK相机,然后显示一个默认的color预览将包含来自设备的RGB相机的缩放预览。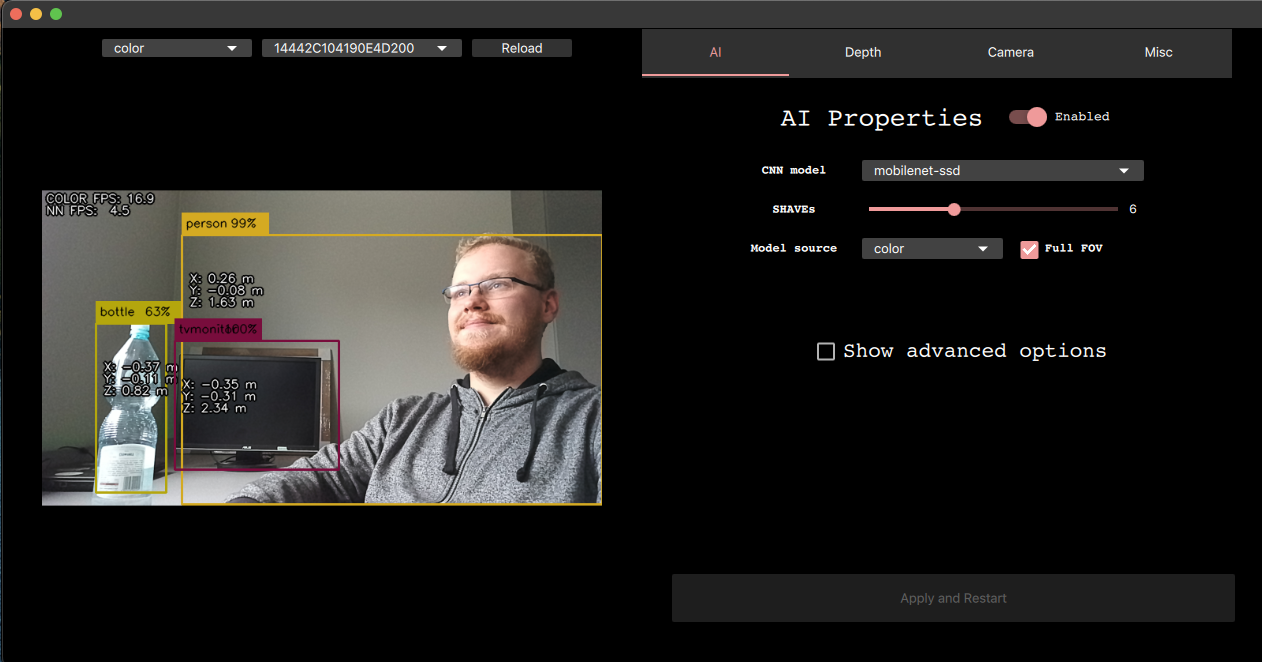
▌更改预览
要查看设备上的其他预览,你可以使用GUI左上角的预览切换器。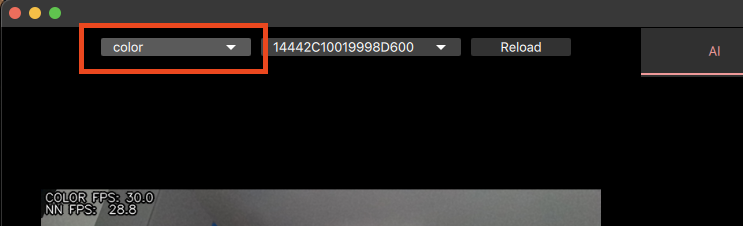
| 名字 | 描述 | 限制 |
|---|---|---|
| color | 显示彩色相机的预览 | |
| nnInput | 显示来自右黑白相机的预览 | 如果没有人工智能模型运行,则禁用 |
| left | 显示左黑白相机的预览 | OAK-D需要 |
| right | 显示右黑白相机的预览 | OAK-D需要 |
| depth | 显示根据以下内容计算的视差图depthRaw预览和喷射着色。最适合可视化深度 | OAK-D需要 |
| depthRaw | 显示原始深度图。最适合基于深度的计算 | OAK-D需要 |
| disparity | 显示设备上生成的视差图 | OAK-D需要 |
| disparityColor | 显示在设备上生成的视差图,并进行喷射着色。应该与相同depth预览,但在设备上生成。 | OAK-D需要 |
| rectifiedLeft | 矫正左相机的帧 | OAK-D需要 |
| rectifiedRight | 矫正右相机的帧 | OAK-D需要 |
▌默认模型
当demo运行时,你可以看到检测结果——如果你站在相机前,你应该看到自己被检测为一个人的概率相当高。
默认使用的型号是MobileNetv2 SSD对象检测器PASCAL 2007 VOC类别,包括:
- 人:人
- 动物:鸟、猫、牛、狗、马、羊
- 交通工具:飞机、自行车、船、公共汽车、汽车、摩托车、火车
- 室内:瓶子、椅子、餐桌、盆栽、沙发、电视/显示器
所以试着检测不同的物体,比如瓶子或苹果
甚至是猫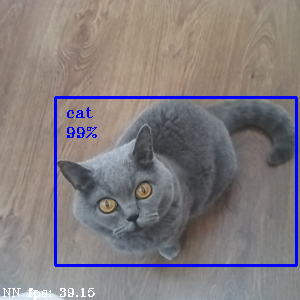
▌使用其他模型
我们准备了其他型号,你可以轻松尝试和评估。运行demo脚本,例如face-detection-retail-0004,点选CNN Model组合框并选择提到的模型。
这将允许你检测人脸,如下图所示
你可以使用此组合框来更改在DepthAI上运行的模型。也可以使用命令行来选择:
$ python3 depthai_demo.py -cnn face-detection-retail-0004
下面是一份你可以使用的模型清单,只需下载demo脚本即可。
| 名字 | 目的 | FPS | 链接 |
|---|---|---|---|
| deeplabv3p_person | 人群细分 | 22.1 | 使用 |
| face-detection-adas-0001 | 人脸检测 | 13.4 | 使用 |
| face-detection-retail-0004 | 人脸检测 | 30.0 | 使用 |
| mobilenet-ssd | 物体检测(20类) | 30.0 | 使用 |
| pedestrian-detection-adas-0002 | 人物检测 | 13.1 | 使用 |
| person-detection-retail-0013 | 人物检测 | 10.7 | 使用 |
| person-vehicle-bike-detection-crossroad-1016 | 人员、车辆和自行车检测 | 6.2 | 使用 |
| yolo-v3 | 物体检测(80类) | 1.9 | 使用 |
| tiny-yolo-v3 | 物体检测(80类) | 29.9 | 使用 |
| vehicle-detection-adas-0002 | 车辆检测 | 14.0 | 使用 |
| vehicle-license-plate-detection-barrier-0106 | 车牌检测 | 30.0 | 使用 |
| openpose2 | 姿态估计 | 6.5 | 使用 |
| human-pose-estimation-0001 | 姿态估计(英特尔) | 7.3 | 使用 |
- deeplabv3p_person允许突出显示图像中检测到人的部分
$ python3 depthai_demo.py -cnn deeplabv3p_person
- face-detection-adas-0001允许检测图像上的人脸(较慢)
$ python3 depthai_demo.py -cnn face-detection-adas-0001 - face-detection-retail-0004允许检测图像上的人脸(更快)
$ python3 depthai_demo.py -cnn face-detection-retail-0004 - mobilenet-ssd检测20个不同类别的对象检测器(默认)
$ python3 depthai_demo.py -cnn mobilenet-ssd - pedestrian-detection-adas-0002允许检测图像上的人物(较慢)
$ python3 depthai_demo.py -cnn pedestrian-detection-adas-0002
- person-detection-retail-0013允许检测图像上的人物(更快)
$ python3 depthai_demo.py -cnn person-detection-retail-0013
- person-vehicle-bike-detection-crossroad-1016允许检测图像上的人、自行车和车辆
$ python3 depthai_demo.py -cnn person-vehicle-bike-detection-crossroad-1016
- yolo-v3可检测80种不同类别的物体检测器(较慢)
$ python3 depthai_demo.py -cnn yolo-v3 - tiny-yolo-v3可检测80种不同类别的物体检测器(速度更快)
$ python3 depthai_demo.py -cnn tiny-yolo-v3 - vehicle-detection-adas-0002允许检测图像上的车辆
$ python3 depthai_demo.py -cnn vehicle-detection-adas-0002
- vehicle-license-plate-detection-barrier-0106允许在图像上检测车辆和车牌(仅限中国车牌)
$ python3 depthai_demo.py -cnn vehicle-license-plate-detection-barrier-0106
- openpose2人体姿态估计模型
$ python3 depthai_demo.py -cnn openpose2
- human-pose-estimation-0001来自Open Model Zoo的人体姿态估计模型
$ python3 depthai_demo.py -cnn human-pose-estimation-0001
我们用来下载和编译模型的所有数据都可以在这里查看。
▌demo用法
在本节中,我们将介绍demo脚本中可用的配置选项,允许你尝试不同的配置。

人工智能属性

切换:
- Enable:打开/关闭人工智能。关闭它将阻止任何神经网络运行,这也将节省一些内存。适用于我们更关注深度/编码而不是人工智能处理的情况。
基本属性:
- CNN模型:选择在DepthAI上运行的模型,更多信息请访问使用其他模型。
- SHAVEs:确定用于编译神经网络的SHAVE核心数。该值越高,网络运行越快,但这也限制了可以一次性启用的功能。
- Model source:指定哪个相机预览作为模型输入,哪些帧将被发送到神经网络以执行推理。
- Full FOV:如果启用,它将缩小图像以符合nn输入尺寸。如果禁用,在缩放之前,它将裁剪图像以满足NN纵横比。
高级选项:
- OpenVINO version:指定将用于编译MyriadX blob和运行管道的OpenVINO版本。大多数情况下,建议使用最新版本。
- Label to count:允许显示demo中可见的特定标签的数量(例如,如果你想在默认模型的预览中计算猫的数量,你可以通过选择
cat作为计数标签并重启脚本) - Spatial bounding box:启用时,将在深度预览上绘制一个边界框,显示检测区域的哪一部分被纳入深度估计。
- SBB Scale Factor:确定空间边界框相对于检测边界框的大小。
深度属性

切换:
- Enabled:打开/关闭深度。关闭它将阻止创建立体节点,这也将节省一些内存。对于我们更关注AI处理/编码而不是深度的情况很有用。
- Use Disparity:如果未设置(默认),demo脚本将根据深度图计算主机上的差异图。如果启用,将在设备上执行相同的处理,这会消耗一些内存,但会限制主机资源的使用。
基本属性:
- Median Filtering中值滤波器:指定应用于深度图的去噪中值滤波器的类型。
- Subpixel亚像素:启用亚像素模式,该模式可提高深度精度,尤其适用于长距离测量。
- Left Right Check左右检查:启用左右检查,用于移除由于对象边界遮挡而导致的计算不正确的视差像素
- Extended Disparity扩展视差:启用扩展视差模式,允许给定的基线有更近的最小距离。
- Depth Range深度范围:指定设备计算的最小和最大距离。
- LRC ThresholdLRC阈值:指定将使像素无效的视差像素之间的最大差异(阈值越高,通过的点越多)
相机属性

基本属性:
- FPS帧率:指定相机捕捉帧的速度。
- Resolution分辨::指定相机传感器分辨率,从而指定捕获的帧大小。
高级选项:
- ISO:控制相机的聚光能力。
- Exposure:控制相机的曝光时间。
- Saturation:控制帧中颜色的浓度。
- Contrast:控制帧中不同色调的视觉比例。
- Brightness:控制帧中颜色的深浅。
- Sharpness:控制框架中细节的清晰度。
混杂的

Recording:
- 开关:启用指定相机的录制。
- FPS输入:指定录制FPS(默认为30)。
- Destination路径:指定一个目录路径,视频将被存储在哪里。
Reporting:
- 开关:启用指定功能的日志记录
- Destination路径:指定一个文件路径,Reporting文件的存储位置
▌使用自定义模型
| ⚠警告!使用自定义模型需要本地下载的depthai资源库的版本。如果你一直使用安装程序来下载和运行脚本,添加自定义模型将无法工作。请按照 “设置“一节说明如何下载和设置资源库。 |
让我们假设你想运行一个从Model Zoo下载的或自己训练的(或两者)的自定义模型,为了使你的模型能够在DepthAI上运行,必须将其编译成MyriadX blob格式——这是你的模型的一个优化版本,能够利用Myriad X芯片作为处理单元。
在我们的demo脚本中,我们支持几种运行自定义blob的方法,将在下面介绍。作为一个例子,我将添加一个名为custom_model(用你喜欢的名字替换)并用demo脚本运行它。
编译MyriadX blob
要接收MyriadX blob,网络必须已经是OpenVINO IR格式(包括.xml和.bin文件),这些文件将用于编译。在这里,我们不会关注如何为你的模型获得这种表示,但是一定要查看官方OpenVINO转换指南。
为了转换custom_model.xml和custom_model.bin,我们将使用blobconverter cli——我们的工具利用了在线MyriadX blob转换器来执行转换。在这种情况下,不需要本地安装OpenVINO,因为所有的依赖项都已经安装在服务器上了。如果你的模型是TensorFlow或Caffe格式,你仍然可以使用我们的工具进行转换,只是要注意,你必须使用不同的输入标志,有时还需要提供一个定制的模型优化器参数(阅读更多)。
首先,让我们从PyPi安装blobconverter。
$ python3 -m pip install -U blobconverter
现在,安装完blobconverter后,我们可以用下面的命令编译我们的IR文件。
$ python3 -m blobconverter --openvino-xml /path/to/custom_model.xml --openvino-bin /path/to/custom_model.bin
通过运行这个命令,blobconverter向BlobConverter API发送请求,以对提供的文件执行模型编译。编译后,API用一个.blob文件,删除随请求一起发送的所有源文件。
成功编译后,blobconverter返回下载的blob文件的路径。因为这个blob是depthai仓库,让我们把它移到那里。
$ mkdir <depthai_repo>/resources/nn/custom_model $ mv <path_to_blob> <depthai_repo>/resources/nn/custom_model
配置
为运行这个blob的demo脚本,我们需要提供一些额外的配置。demo脚本将寻找一个custom_model.json以了解如何配置管道和解析结果的详细信息。
如果你的模型基于MobileNetSSD或Yolo,你可以使用我们的detection输出格式。如果是不同类型的网络,你可以使用默认raw输出格式,并提供自定义处理程序文件来解码和显示NN结果。
你可以使用这些配置示例来自定义你在resources/nn/custom_model目录下的custom_model.json。
- MobileNetSSD(我们将使用此配置)
{
"nn_config":
{
"output_format" : "detection",
"NN_family" : "mobilenet",
"confidence_threshold" : 0.5,
"input_size": "300x300"
},
"mappings":
{
"labels":
[
"unknown",
"face"
]
}
}
- Yolo
{
"nn_config":
{
"output_format" : "detection",
"NN_family" : "YOLO",
"input_size": "416x416",
"NN_specific_metadata" :
{
"classes" : 80,
"coordinates" : 4,
"anchors" : [10,14, 23,27, 37,58, 81,82, 135,169, 344,319],
"anchor_masks" :
{
"side26" : [1,2,3],
"side13" : [3,4,5]
},
"iou_threshold" : 0.5,
"confidence_threshold" : 0.5
}
},
"mappings":
{
"labels":
[
"unknown",
"face"
]
}
}
- Raw(关于如何创建
handler.py文件,请详见自定义处理程序)
{
"nn_config": {
"output_format" : "raw",
"input_size": "300x300"
},
"handler": "handler.py"
}
运行demo脚本
文件准备就绪后,我们现在可以用我们的定制模型运行demo了。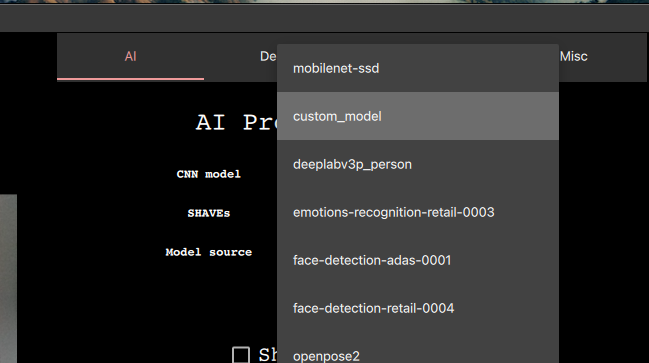
你应该看到输出和你的NN结果被显示出来(如果选择了raw,并且没有处理程序文件,则打印在控制台)。
请务必查看下面的高级部分或参见后续步骤。
自定义处理程序
自定义处理程序是一个文件,demo脚本将加载并执行该文件来解析NN结果。我们用指定这个文件handlerconfig值指定这个文件,指定一个首选文件的路径。它还要求输出raw格式,因为它可以防止脚本自己处理结果。
handler.py文件应该包含两个方法:decode(nn_manager, packet)和draw(nn_manager, data, frames)。
def decode(nn_manager, packet): pass def draw(nn_manager, data, frames): pass
第一种方法,decode解码。每当一个NN数据包从管道到达时就会被调用(存储为packet参数),同时还提供了一个nn_manager对象,其中包含脚本使用的所有nn相关信息(如输入大小等)。这个函数的目标是将从NN blob接收到的数据包解码成有意义的结果,以便以后显示。
第二个,draw函数。是用NN结果(从decode返回)、 nn_manager对象和frames数组调用的,其中有[(<frame_name>, <frame>), (<frame_name>, <frame>), ...]项。该数组将包含用-s/--show参数指定的帧,该函数的目标是将解码结果绘制到接收到的帧上。
下面,你可以找到一个例子handle.py文件,该文件解码并显示基于MobilenetSSD的结果。
import cv2
import numpy as np
from depthai_helpers.utils import frame_norm
def decode(nn_manager, packet):
bboxes = np.array(packet.getFirstLayerFp16())
bboxes = bboxes.reshape((bboxes.size // 7, 7))
bboxes = bboxes[bboxes[:, 2] > 0.5]
labels = bboxes[:, 1].astype(int)
confidences = bboxes[:, 2]
bboxes = bboxes[:, 3:7]
return {
"labels": labels,
"confidences": confidences,
"bboxes": bboxes
}
decoded = ["unknown", "face"]
def draw(nn_manager, data, frames):
for name, frame in frames:
if name == nn_manager.source:
for label, conf, raw_bbox in zip(*data.values()):
bbox = frame_norm(frame, raw_bbox)
cv2.rectangle(frame, (bbox[0], bbox[1]), (bbox[2], bbox[3]), (255, 0, 0), 2)
cv2.putText(frame, decoded[label], (bbox[0] + 10, bbox[1] + 20), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
cv2.putText(frame, f"{int(conf * 100)}%", (bbox[0] + 10, bbox[1] + 40), cv2.FONT_HERSHEY_TRIPLEX, 0.5, 255)
对于自定义人脸检测模型,使用此代码我们会收到以下输出。
我们已经使用这个处理机制来解码deeplabv3p_person,它是demo脚本中可用的网络之一。
按需编译
由于IR格式的文件可能很大,我们既要下载blob又要上传IR格式到服务器,所以我们加入了一个类似OpenVINO的model.yml文件结构,BlobConverter服务器也在内部使用。你可以在OpenVINO Model Zoo或者在demo脚本中的可用模型中查看该文件的外观。
该文件由OpenVINO模型下载器使用,用于下载编译所需的文件。在我们的demo脚本中,我们使用这些文件来提供NN源文件的URL,而不是将它们与源代码一起上传。这也很有用,因为按需编译允许我们使用相同的配置,同时请求不同数量的MyriadX SHAVE核心。
为了使用model.yml文件下载blob,运行一下命令:
$ python3 -m blobconverter --raw-config /path/to/model.yml --raw-name custom_model
你也可以把model.yml文件留在resources/nn/<name>目录内,这将使demo脚本为你执行转换,并运行接收到的blob。
$ python3 depthai_demo.py -cnn <name>
▌定制demo代码
回调文件
如果你想自己添加一些自定义功能到demo中,或者只是检查某些变量看起来如何,你可以使用回调文件,它应该包含demo在执行特定事件时将调用的方法。
下面是一个回调文件的例子,该文件在软件库中可用。
def shouldRun():
pass # Called to determine if the demo should be running
def onNewFrame(frame, source):
pass # Called when a new frame is available
def onShowFrame(frame, source):
pass # Called when a frame is about to be displayed
def onNn(nn_packet):
pass # Called when a new NN packet is available
def onReport(report):
pass # Called when a new report is available
def onSetup(*args, **kwargs):
pass # Called when the demo script is setting up
def onTeardown(*args, **kwargs):
pass # Called when the demo script is finishing
def onIter(*args, **kwargs):
pass # Called on each demo script iteration (internal loop)
这些方法允许在demo脚本本身的基础上建立自定义功能,无论是打印或计算来自NN的数据,还是修改如何显示框架,甚至进行自定义数据库/API连接,将数据发送到外部路径。
默认情况下,demo脚本将使用存储库中的callbacks.py文件,但是这个路径可以使用-cb <path> / --callback <path>标志来改变。
将Demo作为一个类导入
如果愿意,demo脚本也可以像一个普通的类一样被导入,这允许控制demo何时启动,何时运行。下面是一个如何从Python代码中运行demo的简单例子。
from depthai_demo import Demo from depthai_helpers.arg_manager import parseArgs from depthai_helpers.config_manager import ConfigManager args = parseArgs() conf = ConfigManager(args) demo = Demo(onNewFrame=<fn>, onShowFrame=<fn>, onNn=<fn>, onReport=<fn>, onSetup=<fn>, onTeardown=<fn>, onIter=<fn>) # all params are optional demo.run_all(conf)
记住这一点,PYTHONPATHenv变量必须包含depthai仓库的路径,这样导入才会有效。或者,你可以将脚本沿着depthai_demo.py放到仓库里。
▌后续步骤
在前面的部分中,我们学习了如何预览DepthAI的基本功能。从这一点出发,你可以进一步探索DepthAI的世界。
- 寻找灵感?查看我们的用例,了解在DepthAI上姐姐特定问题的现成应用。
- 想开始编码?请务必查看API部分的hello world教程,了解API的详细介绍。
- 想要培训和部署一个自定义模型到DepthAI?访问自定义培训页面,了解随时可用的Colab。