❸如何实现低延迟?

下面的表格显示了,当你接上了USB款的OAK相机(USB 3.2 Gen1 5Gbps),你可以预期的性能。这些测试禁用了XLink分块功能(pipeline.setXLinkChunkSize(0))。如需查看示例代码,请查看延迟测量。
| 分类 | 分辨率 | FPS | FPS set | 主机时间[毫秒] | 带宽 | 柱状图 |
|---|---|---|---|---|---|---|
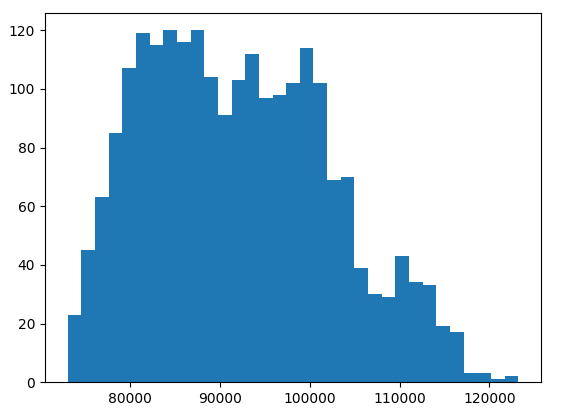
| 彩色(ISP) | 1080P | 60 | 60 | 33 | 1.5 Gbps | 查看 |
| 彩色(ISP) | 4K | 28.5 | 30 | 150 | 2.8 Gbps | 查看 |
| 黑白 | 720P/800P | 120 | 120 | 24.5 | 442/482 Mbps | 查看 |
| 黑白 | 400P | 120 | 120 | 7.5 | 246 Mbps | 查看 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
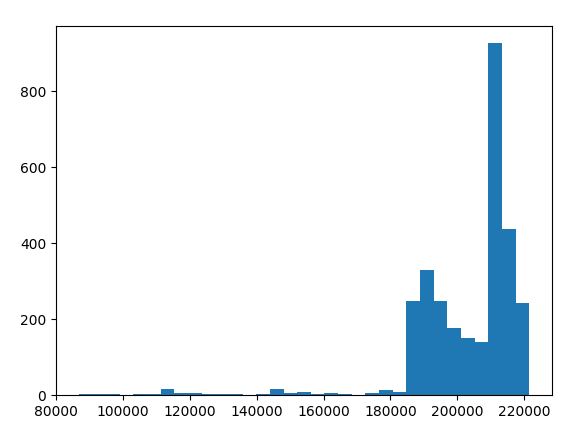
- 主机时间是帧时间戳之间的测量时间(
imgFrame.getTimestamp())和接收帧时的主机时间戳(dai.Clock.now())。 - 柱状图显示主机运行时间因帧而异。y轴代表当时发生的帧数,而X轴代表微秒。
- 带宽是以指定FPS传输指定帧所需的计算带宽。
▌编码帧
| 分类 | 分辨率 | FPS | FPS set | 主机时间[毫秒] | 柱状图 |
|---|---|---|---|---|---|
| 彩色视频H.265 | 4K | 28.5 | 30 | 210 | 查看 |
| 彩色视频MJPEG | 4K | 30 | 30 | 71 | 查看 |
| 彩色视频H.265 | 1080P | 60 | 60 | 42 | 查看 |
| 彩色视频MJPEG | 1080P | 60 | 60 | 31 | 查看 |
| 黑白H.265 | 800P | 60 | 60 | 23.5 | 查看 |
| 黑白MJPEG | 800P | 60 | 60 | 22.5 | 查看 |
| 黑白H.265 | 400P | 120 | 120 | 7.5 | 查看 |
| 黑白MJPEG | 400P | 120 | 120 | 7.5 | 查看 |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
你还可以使用DepthAI的Zero-Copy分支来减少帧延迟,这将把指针(在XLink级别)传递给cv2.Mat,而不是做memcopy(像现在这样),所以性能的提高将取决于你使用的图像大小。(注意:API有所不同,并非所有功能都都可以在message_zero_copy分支上实现。)
▌PoE延迟
PoE上的延迟会因多种因素而有很大差异:
- 网络本身。例如,如果你在一个有许多节点的大型网络中,与使用直接连接相比,延迟会更高。
- 有一个带宽瓶颈:
- 计算机的网络接口卡设置,查看此处文档。
- 100% OAK Leon CSS (CPU)使用率。Leon CSS核心处理POE通信(查看此处的文档),如果CPU被100%使用,它将无法以应有的速度处理通信。
- 另一种改善PoE延迟的潜在方法是微调网络设置,如MTU、TCP窗口大小等。(查看这里了解更多信息)
▌运行神经网络时减少延迟
在上面的例子中,我们只是流媒体帧,没有在OAK相机上做任何其他事情。本节将重点讨论在OAK上运行NN模型时如何减少延迟。
降低相机FPS以匹配NN的FPS
降低FPS,使其不超过NN的能力,通常可以提供最好的延迟性能,因为NN能够在有新帧时立即开始推理。
例如,在15 FPS的情况下,从拍摄时间测量(曝光结束和MIPI读出开始),我们总共得到大约70ms的延迟。
这一时间包括以下内容:
- MIPI读出
- ISP处理
- 预览后处理
- NN神经网络处理
- 传输到主机
- 最后,在它到达应用程序之前会有额外的延迟
注意:如果FPS稍微增加,接近19..21 FPS,会出现大约10ms的额外延迟,我们认为这与固件有关。我们正在积极寻找降低延迟的改进方法。
NN输入队列大小和阻塞行为
如果应用程序有detNetwork.input.setBlocking(False),但队列大小不变,以下调整可能有助于提高延迟性能:
通过添加detNetwork.input.setQueueSize(1),同时将相机FPS设置回40时,我们得到大约80..105毫秒延迟。导致不确定性的原因之一是相机以不同的速度(25ms的帧时间)生产,而NN已经完成并可以接受新的帧来处理。