如果运行的是我们官方的demo,如API里的code samples、Gitee的depthai-experiments、depthai-examples等等出自OAKChina或Luxonis的示例,卡顿可能有以下几种原因:
1.主机性能过低。
虽然blob模型那些功能都是跑在OAK设备里的,不会过多占用主机性能,但跑在不同主机上帧率还是会有差异的。比如同样跑depthai_demo.py,接在树莓派4B上NN和color的帧率能有15fps:
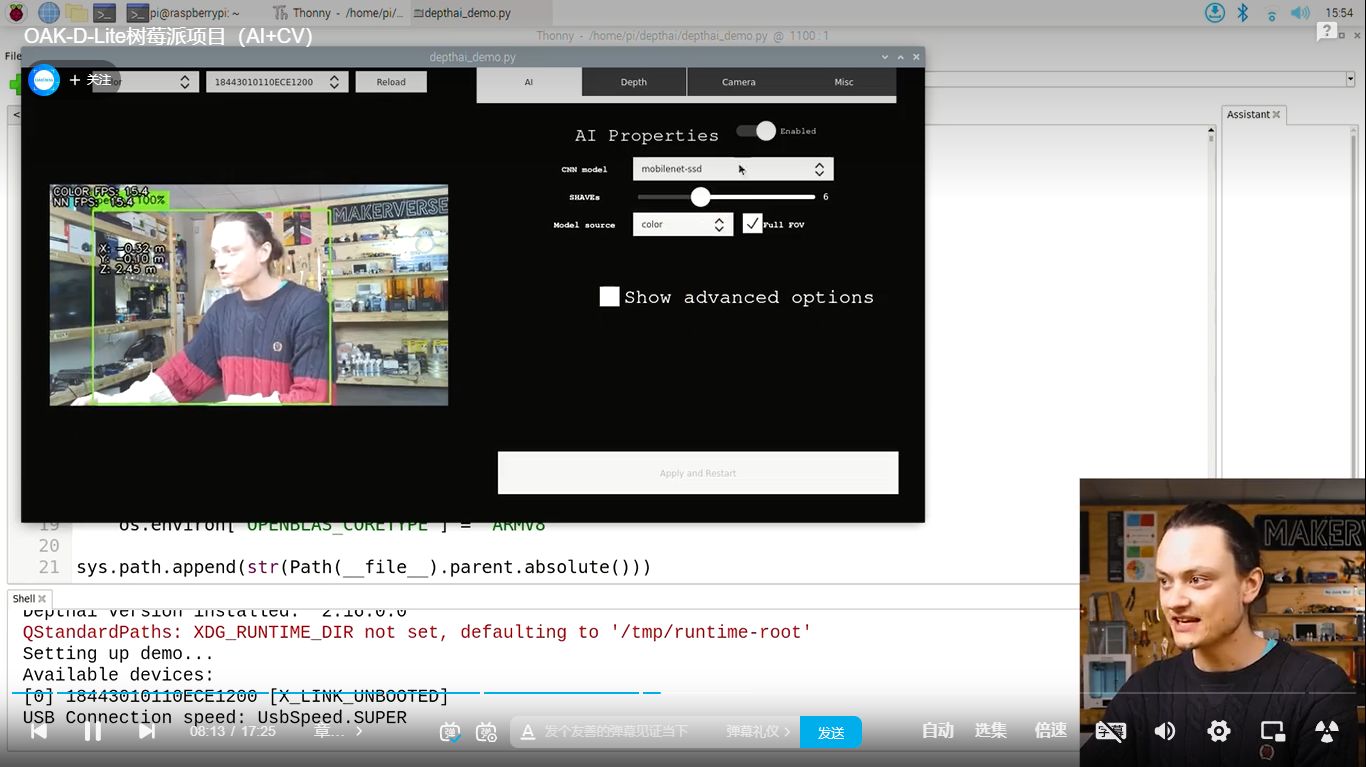
而跑在Pi zero上只有几帧:
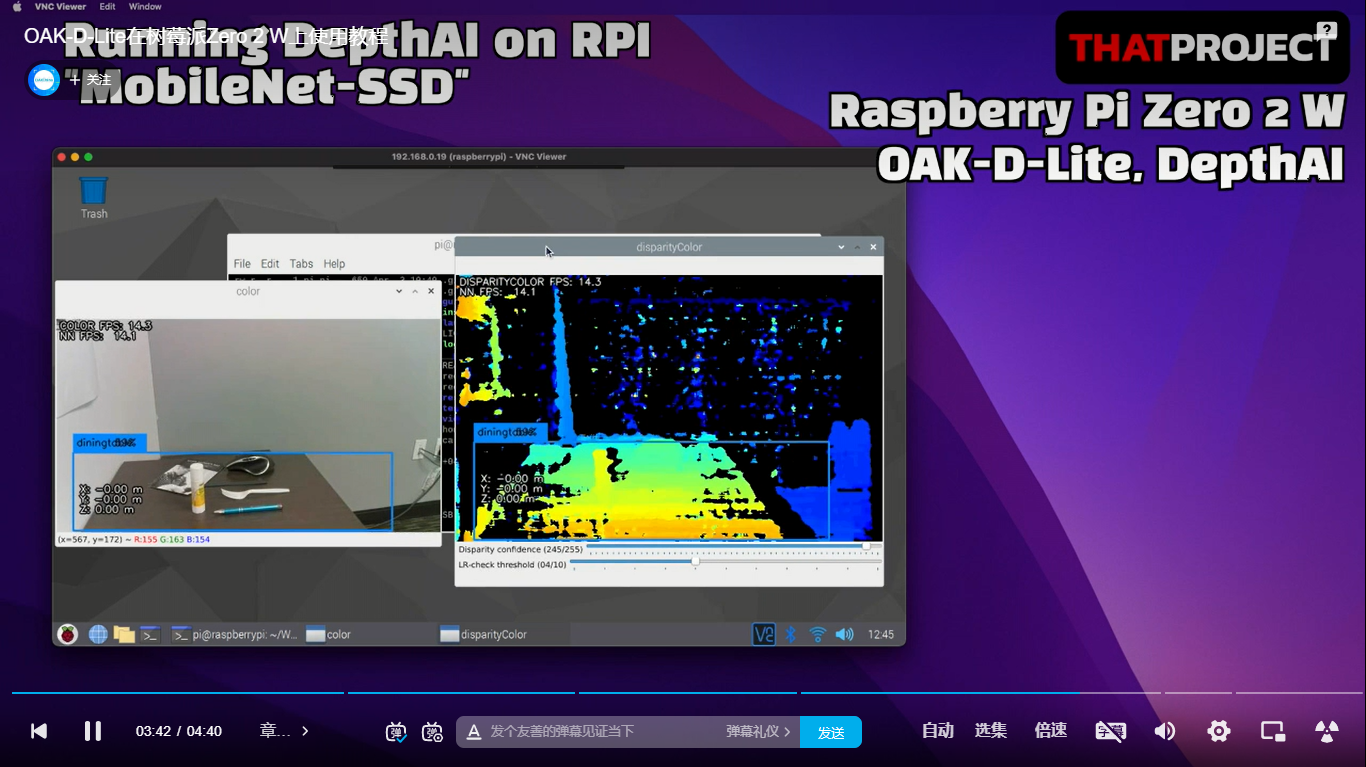
这个应该比较好理解吧,几百块钱的主机和几千块钱的多少还是有区别的。如果你是想用树莓派当主机,又要求帧率不能太低的话,我比较推荐用树莓派4B、3B、CM系列。
2.显示原因。
有的时候主机接口接了不少东西,这个整体一运行起来,preview看起来可能也会有点延迟,你可以尝试一下不preview,直接输入结果,你看看影不影响你的使用。(不能保证不preview后帧率提高很多)
还有一种是你的preview尺寸过大,可以尝试将preview尺寸降低,比如300*300。请自行参考我们API里的code samples中有关preview的示例。
3.模型原因
同样的功能,不同的模型用到OAK上可能也会有差别。比如有的用户也是做yolov5识别,但和官方的yolov5识别相比,用起来帧率就低很多。
另外,不同模型帧率差异也比较大。比如我们官方的人脸检测帧率可以在30fps,而姿态检测可能不超过15fps。一般blob越大、功能越多,运行起来帧率相对会比较低。像这种情况,只能用户自行解决如何优化模型。比如我们之前有用户觉得yolov5帧率比较低,后来改用yolov7,从6fps提高到17fps。
如果你是用的我们别的用户的项目(GitHub上的开源项目),帧率不高也请参考以上三条。